


The Generative Edge Week 32
Mind the spaghettification of AI image generation, dive into the dark depths of uncensored models and meet Stability.ai's new code model

Welcome to week 32 of The Generative Edge, here is the gist in 5 bullet points:
Image generation has evolved rapidly and tools and processes are becoming a lot more complex for those who need it
Different tools cater to various skill levels, with Midjourney/Dall-E for beginners, Auto1111 for technical control, and ComfyUI for full control over every aspect of the pipeline.
Stability AI introduces StableCode, a coding assistance tool trained on open-source data, offering a local alternative to Github's Copilot.
Llama-2-uncensored allows a peek into the dark depths of unaligned language models, but there are legitimate use cases.
The spaghettification of AI image generation
Ah, the good old days of spring 2022. Dall-E just released, and we were all amazed how a single sentence produces to an actual image, our collective minds were blown. Fast forward to just over a year later, and the AI image generation ecosystem has exploded.
New models, workflows, systems are released every week and this truly is a space within generative AI that is hard to keep up.
Naturally, the workflows are evolving as well, and are becoming much more complex, so complex in fact, that some people speak of the spaghettification of image generation process.

ComfyUI is a node based system for AI image generation.
Node systems are common in various 3D image tools like Blender or UnrealEngine; they allow chaining complex pipelines in a visual way
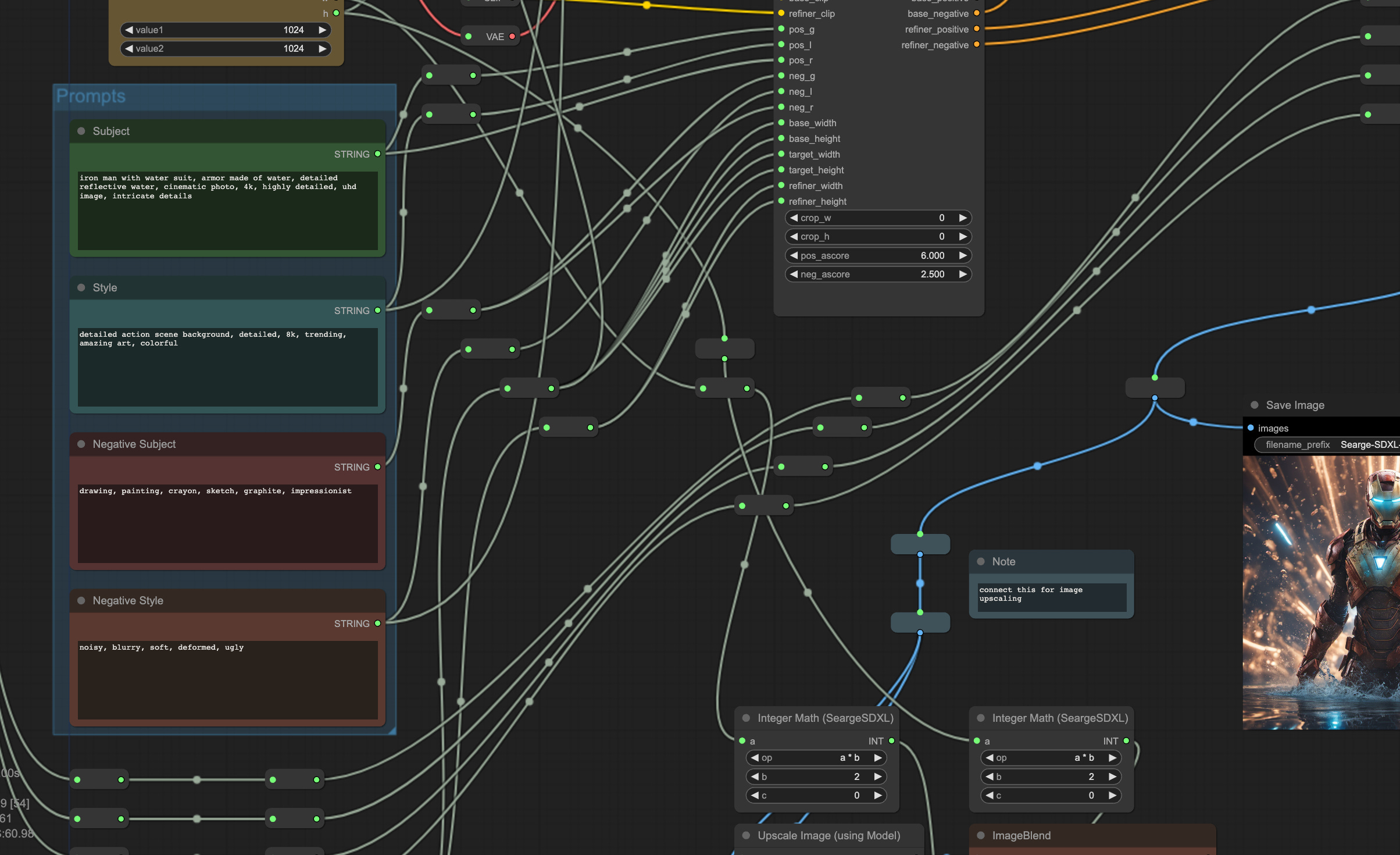
ComfyUI does the same for the Stable Diffusion ecosystem, it allows extremely fine grained control over every step of the generation pipeline
Naturally, with that much power comes a lot of complexity, and grasping the more complex pipelines is no easy feat

Thankfully there are AI image generation tools for every skill and complexity level, among others there are
Midjourney/Dall-E for the easy path, with reliably great outputs, but very little control
Auto1111 for a whole lot of technical control, lots of sliders and plugins
ComfyUI for full control over every aspect of the pipeline
StableCode
As Github’s copilot has established itself firmly in the development environments of many, many developers it has become clear that LLMs, especially those fine-tuned on code, have become an almost essential tool in the toolbox of a software engineer today.
Copilot, based on OpenAI’s Codex, is powerful but it is not free or open, and can’t be run locally or internally. Therefore the emergence of various open code models has be interesting to observe, as they open up opportunities for individuals but also (large) coorporations to make use of LLM assisted development without having to put all of their eggs into the single OpenAI/Microsoft basket.
A new model that was just released is StableCode:

Stability AI, known for its Stable Diffusion text-to-image generation model, has launched StableCode, a large language model designed to generate code.
StableCode is available in three versions: a base model for general use, an instruction model, and a long-context-window model capable of supporting up to 16k tokens (double the amount of GPT-4, and the same as GPT3.5-16k)
The model is initially compatible with Python, Go, Java, JavaScript, C, markdown, and C++ programming languages.
StableCode is trained on data from the open-source BigCode project, with additional filtering and fine-tuning from Stability AI.
Unlike other models, StableCode uses rotary position embedding (RoPE) instead of the ALiBi approach, which changes how the model weighs tokens at the beginning vs the end and reflects how natural language should be treated differently from code.
Find more information here: https://stability.ai/blog/stablecode-llm-generative-ai-coding
The dark depths of uncensored models
Most language models you interact with are “aligned”, which is just a fancy word for censored. Now that’s not necessarily a bad thing, you really don’t want your LLM spouting racist, sexist or dangerous stuff as you integrate it into your workflows, especially not if you use it inside your organization and most definitely not if they’re customer facing.
That said, aligning a language model isn’t a free lunch and forcing the LLM to ignore parts of its training data (because again, racist, sexist, biased, dangerous, etc.) leads to a sort of lobotomization effect, where the general ability of the model suffers. Usually that’s a worthy tradeoff, but it is one to be aware of.

A version of the recently released Llama 2 model has been instruct fine tuned in a way that disables most censorship and alignment (source)
Examples for censored (GPT-4) and uncensored (Llama 2 uncensored) outputs:




There are use cases that aren’t nefarious that can benefit from a lack of alignment, like software security related tasks, fiction but also mundane tasks like stripping privacy sensitive data from a given text - tasks that aligned models might flat out refuse.
If you want to play around with an uncensored model and have a recent-ish MacBook, check out ollama: github.com/jmorganca/ollama
… and what else?
NVIDIA releases their new GH200 chips with even more memory, which will enable even larger models to be trained and run (source)
And that’s it for this week!
Find all of our updates on our Substack at thegenerativeedge.substack.com, get in touch via our office hours if you want to talk professionally about Generative AI and visit our website at contiamo.com.
Have a wonderful week everyone!
Daniel
Generative AI engineer at Contiamo
